Подпишитесь
на мой канал
на мой канал
 Подписаться
Подписатьсяна телеграм Подписаться
на макс

13 лет опыта
Ивчевски Игор
Специалист по интернет-маркетингу с сайтоцентричным подходом
Чтобы страницы сайта участвовали в поиске и занимали какие-либо позиции по ключевым запросам, они должны быть успешно просканированы и проиндексированы поисковым роботом. Если сайт не полностью индексируется, он недополучит органического трафика (посетителей из поиска).
Правильная настройка индексации сайта является первым и фундаментальным этапом работы над поисковым продвижением сайта и к ней нужно подойти серьезно и основательно.
Задачи анализа индексации сайта — две:
Итоговая задача: выяснить конкретные ошибки, устранить их или запланировать и реализовать другие работы по индексированию всех продвигаемых страниц сайта.
Для того, чтобы проверить и выявить ошибки в индексации поисковым роботом Яндекса, сделаем 3 анализа и получим 3 отчета помощью встроенного инструмента в панели для вебмастеров от Яндекса.
Первым делом стоит проверить какие страницы сайта Яндекс не включил в поиск и по какой причине.
Где смотреть: Яндекс Вебмастер > Индексирование > Страницы в поиске > Исключенные страницы.

Выгружаем список всех страниц. Для этого в правом нижнем углу есть кнопка Скачать таблицу в CSV или XLS формате.
Помощью данного анализа мы можем узнать важный момент: не исключены ли из поиска полезные, продвигаемые и нужные страницы. Если да, ищем причину и создаем ТЗ на исправление ошибок и план работ по возвращению страниц в поиск.
Отметим, что исключение страниц по причине “неканоническая” и “редирект” нормальный процесс. Это означает что страницы скорее всего дублировались и в поиске заменены другими.
Стоит особенно серьезно отнестись к:
Это отчет о всех страницах, участвующих в поиске Яндекса.
Где посмотреть: Яндекс Вебмастер > Индексирование > Страницы в поиске > Все страницы. Выгрузить список можно так же, как и предыдущий отчет.
Какие выводы нужно сделать:
Отчет покажет нам какие страницы сайта поисковый робот обошел, просканировал (т.е. о существовании каких страницах робот в принципе знает). Не путать с “проиндексировал”!
Где посмотреть: Яндекс Вебмастер > Индексирование > Статистика обхода > Все страницы.

До анализа нужно убедиться, что в выгруженном списке нет дублей URL.
С помощью анализа индексации в Google Search Console мы выясняем те же вопросы:
В разделе “Страницы” Search Console можно сразу наглядно увидеть 2 отчета:
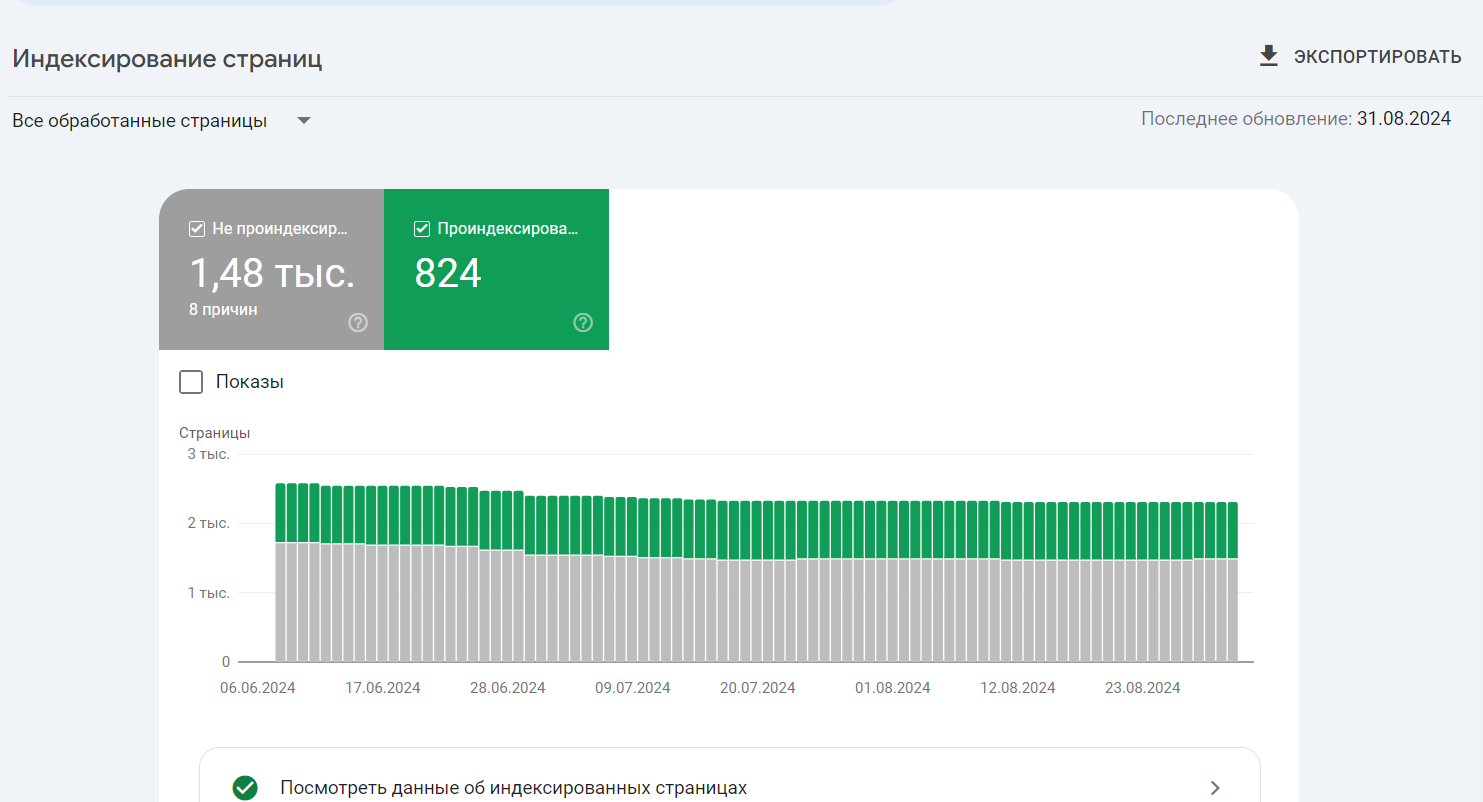
Где смотреть: GSC > Страницы > Почему эти страницы не индексируются.

В отчете видны несколько групп страниц, разделенные на основе причины, из-за которой не попали в индекс.
Анализируем исключенные страницы и выявляем между ними нужные, продвигаемые страницы. Потом составляем задание на исправление ошибок и дальнейшую индексацию страниц.
Повторимся здесь тоже, что исключение страниц по причинам “Неканоническая” “Запрещено элементом noindex”, “Заблокировано в файле robots.txt” и “Переадресация” — скорее всего решение, а не проблема, как было сказано выше в теоретической части. Это означает что страницы скорее всего дублировались и в поиске заменены другими, либо осознанно оттуда исключены.
Чуть ниже объясню что с такими страницами делать.
Особенно обратить внимание на:
Где смотреть: GSC > Страницы > Посмотреть данные об индексированных страницах

Этот отчет показывает страницы, которые проиндексированы роботом Google. Но, возможно, среди них находятся страницы, которые не должны там быть.
Поэтому стоит проанализировать URLs, хотя бы выборочно.
Screaming Frog SEO Spider — мощная SEO программа, настоящий комбайн. Помощью нее можно решать разные SEO-аналитические задачи, в т.ч. анализ индексации. Программа довольно проста в работе, с понятный интерфейсом (правда, на английском). Для сканирования до 500 урлов — бесплатная.
Как проверить в ней индексацию я рассказывал в видео.
ComparseR — программа в которой очень удобно и просто определить индексацию. По заявлениям разработчика, именно это и является ее основной задачей и отличием от многих других SEO программ и сервисов. Основная ценность компарсера не просто в парсинге страниц сайта, а в сравнении полученных данных при парсинге самого сайта с данными из выдачи поисковиков, что быстро дает понять, какие страницы сайта не индексируются, а какие страницы в индексе, а не должны быть там.
Программа работает просто, но медленно (иногда и сутки требуются). На выходе получаете вот такой файл. Правда, это файл уже после небольшой обработкой — но все данные в нем выдает программа.
После проведения анализов и получения отчетов, нужно провести сравнительную аналитику и выводы.
Стоит дополнительно обратить внимание на индекс Google. Хоть это и неофициально, считается что у него есть основной и дополнительный индекс. В основном находятся страницы которые участвуют в поиске по целевым фразам, а в дополнительном — те, которые не участвуют, или участвуют очень редко. Иными словами, страницы из дополнительного индекса Google — c одной стороны проиндексированы, с другой, бесполезны, т.к. не показываются в поисковой выдаче.
В дополнительный индекс обычно попадают некачественные страницы, дубли, страницы на которых мало контента и т.п. Словом — мало полезные. Единственный способ чтобы они попали в основной индекс — сделать их качественными и полезными. Добавить больше уникального контента, не повторять содержимое других страниц сайта, устранить технические дубли (об этом подробнее дальше), и т.п.
Нужно в поиске гугл использовать специальные формулы.
Общее число проиндексированных страниц можно получить помощью запроса “site:site.ru”.
Страницы из основного индекса (которые участвуют в поиске) можно получить по запросу “site:site.ru/&”.
Разница — страницы из дополнительного индекса Google, редко участвующие в поиске. Это конечно предполагает дополнительную ручную работу, но специализированного софта для надежного решения таких задач нет.


Частые перебои в работе сайта усложняют его взаимодействие с поисковыми роботами (он часто оказывается для них недоступным), что затрудняет индексацию. Из-за частых перебоев сайт вообще может быть даже полностью исключен из поиска.
Главную роль в стабильности работы и доступности сайта играет не сам сайт, а стабильность сервера, на котором он размещен. Сервера обычно арендуют у хостинг-провайдеров в разных формах: виртуальный хостинг, VPS, аренда выделенных серверов. Самый простой и доступный: виртуальный хостинг (по сути аренда места в облачном хранилище провайдера).
Очень важно серьезно подойти к выбору хостинга. Главный параметр – высокий аптайм (uptime). Это время непрерывной доступности ресурса (сайта/хостинга/сервера), и у хороших хостингов он достигает отметку в 99,95%. Рекомендую пользоваться хостингом beget.com. Это современный, надежный и проверенный временем провайдер.
Код ответа сервера — это три цифры, выдаваемые сервером в ответ на вводимый запрос, в которых зашифрована информация о состоянии страницы.
Неправильные ответы серверов могут помешать корректной индексации сайта. Важно убедиться, что они настроены корректно.
Проверить можно в одной их многих программ парсеров сайта (например Screaming Frog SEO Spider), а также встроенными инструментами в панели для вебмастеров.

Главные коды ответов серверов:

Рассказываю о том, как малому бизнесу зарабатывать в разы больше денег с помощью интернет-маркетинга и эффективного сайта
Есть и другие, но это были самые значимые и часто встречаемые на практике.
Служебный текстовый файл, в котором содержится важная информация для поисковых систем. По сути, это файл для управления индексацией сайта (хоть и считается рекомендательным).
В нем указывается:
Также указывают дополнительную информацию:
Robots.txt должен содержать все необходимые директивы, но с другой стороны не нужно перестараться — вносите в файл только нужное, без лишних указаний.
Убедитесь, что в robots.txt:

Страницы-дубли на сайте появляются из-за технических настроек и особенностей систем управления сайтами, появления динамических параметров к некоторым URL-адресам или в результате целенаправленной работы с сайтом.
Кроме дублирования страниц, проблемой представляют динамические, автоматически генерируемые страницы (URL-адреса) на сайте — они не должны индексироваться.
Есть три способа борьбы с дублями и ненужными страницами на сайтах:
Переадресация с одной страницы на другую (301 редирект) используется всегда, когда дубли страниц бесполезны и не нужны. Настройка редиректа приведет к тому, что поисковая система поймет, что индексировать нужно одну из них (ту, на которую ссылаются). Но, повторимся, т.к. это важно: это только если эти дубли появляются “сами по себе”, не имеют смысла, и одной такой страницы достаточно.
Например, из-за особенностей CMS сайта адреса главной и/или внутренних страниц могут дублироваться. Самый простой пример, когда главная страница доступна и через “www”, и без него. Это классическое дублирование, для поисковика это два разных адреса. Важно, чтобы все страницы сайта (главная и внутренние) всегда открывались только по одному URL адресу. Для этого нужно настроить 301 редиректы:
Бывают ситуации, когда дубли делаются целенаправленно, и они необходимы. Например, дубли (или практические дубли, мало отличающиеся между собой) появляются когда нужно один товар разместить в разных категориях, или товар отличается только по цвету.
В таком случае можно указать какая из двух или нескольких страниц-дублей — главная (каноническая). Для этого используется атрибут rel=»canonical».
Тогда не будет происходить переадресация, пользователям будут доступны обе страницы, но поисковый робот будет индексировать одну из них.
Частые случаи использования канонизации:
Важно, чтобы правильно и только один раз на странице использовать «rel=canonical».
Страницы не должны ссылаться сами на себя (это частая ошибка, когда стоит атрибут canonical указывая на эту же страницу), а исключительно на каноническую страницу на сайте («более главную» страницу с таким же контентом).
Отметим, что в случае со страницами пагинации можно поступить по-другому — уникализировать их. Сделать так, что контент и текст на порядковых страницах 2-3-4 и т. д. — НЕ дублируется, у каждой страницы свое наполнение. Но если их много и сайт большой — это трудный путь.
Кроме дублей, иногда создаются автоматические страницы, и страницы с различными параметрами, бесполезными для пользователей. Их индексацию нужно запретить в robots.txt:
Дополнительный способ борьбы со страницами с разными параметрами — директива Clean-param. Правда, работает только для Яндекса. Помощью данной директивы в файле robots.txt можно указать поисковику не учитывать динамические GET-параметры (например, идентификаторы сессий, пользователей) или метки (например, UTM).
Если существуют сайты, дублирующие основную версию сайта, в избежании проблем с индексацией в Яндексе нужно загрузить к ним идентичный robots.txt, что и к основному сайту.
В случае с Google нужно для всех страниц дублирующих сайтов использовать атрибут rel=»canonical».
Самый надежный способ узнать, существуют ли дубликаты сайта — вспомнить :-). Нет ли тестовые версии разработки, поддомены, не переезжал ли сайт, а старая версия осталась рабочей, и т.п.
Файл sitemap.xml — служебный документ, в котором содержится полный список всех URL адресов на сайте. Здесь поисковая система может быстро найти и проиндексировать все страницы сайта.
Несколько правил составления XML карты:
Сгенерировать sitemap.xml можно внешними сервисами-генераторами или дополнительными модулями для CMS (систем управления сайтами). После создания нужно загрузить в корень сайта и указать адрес на нее в Яндекс Вебмастер и Google Search Console.
HTML карта сайта, в отличие от sitemap.xml — обычная страница на сайте (т.е. это не xml файл) с ссылками на все страницы сайта, на которые вы хотите чтобы поисковый робот точно попал. Для совсем небольшого сайта ее можно создать руками, а для больших или средних сайтов можно использовать плагины для CMS (например Hierarchical HTML Sitemap для WordPress или Sitemap для Drupal). HTML карта, возможно, не обязательна, и индексация может пройти исправно и без нее, но она нередко используется и пользователями, особенно если сайт большой и с неидеальной навигацией.
Технический аудит — это анализ и оценка технических параметров сайта. Поисковые системы уделяют им серьезное внимание и считают их важным фактором ранжирования в результатах поисковой выдачи.
На техническое состояние сайта влияют его наполнение, настройки и особенности CMS (система управления сайтом), настройки и особенности сервера и хостинга, и то, как сайт был сделан разработчиком (чистый и правильный код, использование разных технологий, скриптов, плагинов и модулей).
Но не все технические факторы при этом имеют одинаковый вес — есть более и менее важные.
Скорость загрузки сайта имеет важное значение, как для поисковых систем, так и для пользователей. Согласитесь, вы не стали бы ждать загрузку сайта 10-15 секунд, а скорее бы перешли уже на следующий.
Идеальное время загрузки — до 2 сек. Приемлемое — до 4-5 сек., не больше.
Самый популярный инструмент измерения скорости загрузки — от Google. Но есть важный нюанс: он не измеряет фактическую скорость загрузки, а всего лишь процент от максимально возможного. Там вы не увидите скорость в секундах, а значение в процентах, а также что можно исправить, чтобы ускорить сайт. Считается, что если в зеленой зоне (90-100 баллов) — это отличный результат. 70-90 — достаточный.
Ниже 50 — обязательно требует исправление недочетов.

Для реального измерения скорости загрузки есть несколько других сервисов: loading.express, sitespeed.ru или sitespeed.me.
Главное, чтобы сайт был удобен для просмотра с мобильных устройств. Я лично предпочитаю адаптивную версию, но если у вас есть причины делать отдельную мобильную версию сайта, я не против :-).
Главное, чтобы сайт проходил мобильную валидацию от Яндекса и Google, и, даже более важно — чтобы действительно было удобно пользоваться сайтом с телефона.
Когда говорим об адаптивности, стоит еще упомянут кроссбаузерность — т.е. адаптивность сайта под разные браузеры (Яндекс Браузер, Хром, Мозилла, и т.п.).
Проверить можно вручную, или такими сервисами как browsershots.org или browsera.com.
Частично урлы на сайте создаются автоматически, системой управления сайтами, частично создает их администратор сайта (при создании новых страниц, первая часть обычно задана в настройках системы, а завершающую задает вебмастер).
В адресе, site.ru/catalog/category/tovar1 например, /catalog/category/ скорее всего заданы на уровне CMS, а /tovar1 задается руками при создании новой страницы на сайте.
Нужно настроить систему и аккуратно вписывать ручные адреса, для того чтобы URL адреса соответствовали нескольким правилам:
Использование защищенного протокола уже является обязательным фактором ранжирования и в Яндексе и в уже подавно в Google. Обязательно приобретите SSL сертификат и настройте доступность сайта только через защищенный HTTPS протокол.
Несколько правил использования SSL и Https:
Перечисляем внедрение микроразметки в технические работы, потому что по факту это работа для технического специалиста. Но отношения к техническому состоянию сайта она не имеет. И без нее сайт работает исправно.
Микроразметка помогает поисковым системам лучше понять о чем сайт, что на нем, и какие данные взять с сайта для показа расширенного сниппета в результатах поисковой выдачи.
Сниппет – это краткая информация, которая показывается в выдаче вместе с ссылкой на сайт.
Расширенный сниппет улучшает представление сайта в поисковой выдаче, пользователям понятнее что тут, и они охотнее переходят на сайт. Для расширенного сниппета используются данные, размеченные микроразметкой.


Самая популярная и рекомендуемая Яндексом и Google микроразметка — Schema.org. Помощью микроразметки schema.org можно размечать товары и их стоимость, отзывы, контакты, статьи, изображения.
Видео про микроразметку Schema.org.
Существует еще и стандарт разметки Open Graph. Он позволяет контролировать представление сайта при публикации ссылки в социальных сетях. Чтобы было красивое превью, а не просто ссылка — тем самым увеличивая вероятность взаимодействия с пользователями.
Видео про микроразметку Open Graph.
Перечислим несколько сервисов и программ, помощью которых можно в т.ч. проверить все то, о чем шла речь выше (и не только).
Техническая исправность сайта влияет на восприятие его поисковыми системами, а этим и на ранжирование и позиции в результатах выдачи. Особенно если на сайте допустить весомые ошибки. Поэтому не пренебрегайте этой частью оптимизации сайта — она очень важна.
Но помните: техническая часть — больше для роботов. А ваш сайт — для людей. Уделяйте не меньше внимания его наполнению, качеству контента, удобству, пользы которой он дает вашим пользователям. И все будет хорошо!

и о Вас узнают в 5-10-15 раз больше потенциальных клиентов?
Я могу быть полезен вам и вашему бизнесу. Задам правильные вопросы и расскажу об основных принципах построения системного Интернет-маркетинга.
Свяжитесь со мной – и вы получите свежий и объективный взгляд на текущую ситуацию и идеи роста. Или оставьте заявку на бесплатную консультацию, и я сам свяжусь с Вами.




Сопровождение, консультирование и контроль подрядчиков и/или штатных сотрудников.
от 39 тыс. руб.Связаться
В канале рассказываю про системный интернет-маркетинг, эффективные бизнес-сайты и увеличение прибыли бизнеса в целом через маркетинг.
Подписаться на телеграм Подписаться на Макс




